| Тег для создания таблицы.
|
|
|
Определяет тело таблицы.
|
| |
|
Создает ячейку таблицы.
|
|
|
Используется для объявления фрагментов HTML-кода, которые могут быть клонированы и вставлены в документ скриптом. Содержимое тега не является его дочерним элементом.
|
|
|
Создает большие поля для ввода текста.
|
|
|
Определяет нижний колонтитул таблицы.
|
|
|
Создает заголовок ячейки таблицы.
|
|
|
Определяет заголовок таблицы.
|
|
|
Определяет дату/время.
|
|
|
Заголовок HTML-документа, отображаемый в верхней части строки заголовка браузера. Также может отображаться в результатах поиска, поэтому это следует принимать во внимание предоставление названия.
|
| |
| Создает строку таблицы.
|
|
|
Добавляет субтитры для элементов и .
|
|
|
Выделяет отрывок текста подчёркиванием, без дополнительного акцента.
|
| |
Создает маркированный список.
|
|
|
Выделяет переменные из программ, отображая их курсивом.
|
|
|
Добавляет на страницу видео-файлы. Поддерживает 3 видео формата: MP4, WebM, Ogg.
|
|
|
Указывает браузеру возможное место разрыва длинной строки.
|
Таблица-шпаргалка с тегами
Для удобства пользования я сгруппировала теги по тематическим разделам, добавив значения свойства display для каждого тега. Чтобы перейти к таблице, кликните по рисунку.
Синтаксис HTML
В этой статье мы рассмотрим синтаксис HTML
и как правильно записывать код языка HTML.
Структура HTML-документа
При написании HTML-кода в блокноте, желательно придерживаться одного стиля. Схема стандартного HTML-документа, выглядит следующим образом:
Название страницы
Заголовок статьи
Абзац
статьи
Каждый HTML-документ должен начинаться со строки , она означает что код в документе будет написан на языке HTML. Затем идёт сам HTML-код .
Между тегами располагаются два основных блока, первый блок — это голова HTML-документа
, который начинается и заканчивается тегами , второй блок — это тело HTML-документа
, который начинается и заканчивается тегами .
В голове HTML-документа
содержится различная служебная информация, которую пользователь не видит (кроме тега title
), там находятся следующие теги:
— название HTML-страницы,
— мета-теги, в них содержится служебная информация о странице,
— тег ссылающийся на внешние файлы, например .css
, .ico
и т.д.,
— теги могут содержать JavaScript-код или ссылаться на внешний файл .js
В теле HTML-документа
обычно содержится основная информация, которую мы видим на странице, там могут находиться следующие теги:
— заголовок статьи, первого уровня,
![]() — изображение, — изображение,
— абзац,
— ссылка,
— таблица,
— форма ввода данных,
и т.д.
Правила написания HTML-кода
Рассмотрим некоторые правила написания HTML-кода. Данные правила нужны для того, чтобы потом удобно было разбираться в собственном коде.
- Блочные теги
которые находятся внутри других тегов, лучше размещать на одну строку ниже и на один пробел (табуляцию, как вам удобней) правее от тега в котором он размещен. Например таким образом расположены заголовок h1 и абзац p , по отношению к тегу body , в схеме HTML-документа расположенной в начале этой статьи.
- Закрывающий и открывающий теги одного элемента, могут находится либо на одном уровне, как например теги , либо закрывающий тег может находится в конце текста, как например закрывающие теги элементов title , h1 и p .
- Равнозначные между собой элементы тоже можно размещать на одном уровне, в схеме HTML-документа что расположена выше, равнозначными по отношению друг к другу, являются head и body , h1 и p .
- На самом деле, весь HTML-код можно записать в одну строку и браузер всё равно правильно покажет HTML-страницу. Правила синтаксиса языка HTML, где теги нужно записывать друг под другом и левее, существуют лишь для того, чтобы вебмастеру было удобнее создавать и изменять в дальнейшем код HTML-страницы.
Вот еще некоторые моменты, которые нужно учитывать при создании кода:
Сколько бы вы не поставили пробелов в текстовом редакторе
, браузер покажет их как один пробел.
Переносы строк и табуляции в текстовом редакторе, не распознаются браузером.
Если вам нужно перенести строку, которая должна быть видна на HTML-странице
, то используйте тег
.
Если вам нужна табуляция (например для создания "красной" строки), которая должна быть видна на HTML-странице, то используйте либо несколько спецсимволов неразрывного пробела либо CSS-свойство text-indent .
HTML5 возвращает нас к стилю десятилетней давности, когда практиковалось не закрывать некоторые теги, писать значения без кавычек и по желанию набирать теги в верхнем или нижнем регистре. Такая вольность не означает, что любые правила должны игнорироваться, по-прежнему следует соблюдать корректную вложенность тегов и вставлять обязательные элементы. Отход от жёсткого синтаксиса XHTML позволяет сосредоточиться на содержании сайта, а не на соблюдении пустых формальностей, большинство из которых вызывает раздражение из-за своего несущественного значения и ненужности.
Элементы HTML
Базовым кирпичиком веб-страницы выступает элемент. Они могут делиться по разным критериям, например, по типу или своему назначению.
Элементы по типу
Пустые элементы
К ним относятся элементы, у которых нет закрывающего тега:
,
,
,
,
,
,
, ![]() ,
,
,
,
,
,
,
,
.
,
,
,
,
,
,
,
,
.
Необрабатываемые текстовые элементы
Предназначены для вывода скриптов или стилей, имеющих синтаксис отличный от HTML:
,
.
RCDATA
Эти элементы могут содержать любой текст или спецсимволы, за исключением нестандартных спецсимволов, которые называются сомнительным амперсандом, например: &copi; или &T. К этой группе элементов относятся
и
.
Инородные элементы
Элементы, относящиеся к MathML или SVG.
Обычные элементы
Все остальные элементы, которые не входят в предыдущие группы.
Элементы по назначению
Корневой элемент
Элемент
.
Метаданные документа
, а также элементы, которые располагаются внутри него.
Скрипты
Скрипты позволяют добавлять интерактивности на веб-страницу, в эту группу входят элементы, управляющие скриптами.
Структурные элементы
Элементы, управляющие основными разделами веб-страницы, вроде
,
,
,
,
и др.
Группирование контента
Элементы, обрамляющие текст, списки, изображения.
Текст
Элементы, изменяющие вид текста, например, делающие его жирным или курсивным, а также выделяющие текст по смыслу - аббревиатура, цитата, переменная, код и т.д.
Рецензирование
Элементы
и
показывающие редактирования в документе.
Внедряемый контент
Элементы, вставляемые на страницу в виде разных объектов - изображения, видео, аудио и др.
Табличные данные
Элементы для создания и управления видом таблиц.
Формы
Формы являются одним из важных элементов любого сайта и предназначены для обмена данными между пользователем и сервером. В эту группу входят элементы для создания формы и её полей.
Интерактивные элементы
Специальные виджеты, с помощью которых пользователь может получать дополнительную информацию или управление.
Ссылки
Элементы
и
.
Подобное группирование условно и может принимать другой вид, потому что одни и те же элементы могут принадлежать разным группам.
Теги
Для обозначения начала и конца элемента применяются теги. Внутри тегов могут быть атрибуты со своими значениями, расширяющими возможности тегов, а также содержимое (рис. 1).
Рис. 1. Тег с атрибутом href
Закрывающий тег похож на открывающий, но содержит слэш (/) внутри угловых скобок.
Пустые элементы не имеют закрывающего тега и содержимого (рис. 2).
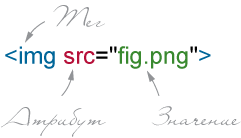
Рис. 2. Пустой тег ![]()
Атрибуты тегов расширяют возможности самих тегов и позволяют гибко управлять различными настройками отображения элементов веб-страницы. Общее количество атрибутов достаточно велико, но их значения, как правило, можно сгруппировать по разным типам, например, задающих цвет, размер, адрес и др. Например, элемент ![]() добавляет на веб-страницу изображение, при этом адрес графического файла мы указываем через атрибут src
.
добавляет на веб-страницу изображение, при этом адрес графического файла мы указываем через атрибут src
.
Доктайп
предназначен для указания типа текущего документа - DTD (document type definition, описание типа документа) для того, чтобы браузер понимал, с какой версией HTML он имеет дело. Если доктайп не указан, браузеры переходят в режим совместимости, в котором не работают многие возможности HTML5, а также возникают ошибки с отображением документа.
Доктайп не чувствителен к регистру и содержит всего два слова:
Это ключевой элемент и обычно он располагается в первой строке кода.
Комментарии
Некоторый текст можно спрятать от показа в браузере, сделав его комментарием. Хотя такой текст пользователь не увидит, он все равно будет передаваться в документе, так что, посмотрев исходный код, можно обнаружить скрытые заметки.
Комментарии нужны для внесения в код своих записей, не влияющих на вид страницы. Начинаются они тегом
. Все, что находится между этими тегами отображаться на веб-странице не будет.
Необязательные теги
Если какой-то тег не указан, это не означает, что он не представлен вообще. Существуют определённые правила, позволяющие не писать некоторые теги. В табл. 1 представлены теги, которые можно не указывать и условие, при котором это происходит.
Табл. 1. Необязательные теги
Тег
Условие
|
|
|
|
|
|
|
|
Если внутри имеются другие элементы.
|
|
|
|
|
|
Если пустой, а также содержит что-то кроме пробела или комментария.
|
|
|
|
|
|
Если после элемента следует |
|
|
Если после элемента следует
или
.
|
|
|
Если после элемента следует
,
или он последний у родителя.
|
|
|
Если после элемента следует
,
,
,
,
,
,
,
,
,
,
,...,
,
,
,
,
,
,
,
,
,
,
,
.
|
|
Если после элемента следует
или
.
|
|
|
Если после элемента следует
или
.
|
|
|
Если после элемента следует
или он последний у родителя.
|
|
|
Если после элемента следует
,
или он последний у родителя.
|
|
|
Если первым внутри идёт
и не следует перед другим элементом
.
|
|
|
|
|
|
Если после элемента следует
или
.
|
|
|
Если первым внутри идёт |
и не следует перед
,
или
у которых опущен закрывающий тег.
|
|
Если после элемента следует
или
или он последний у родителя.
|
|
|
Если после элемента следует
или он последний у родителя.
|
|
Если после элемента следует |
или он последний у родителя.
|
Если после элемента следует |
или
или он последний у родителя.
|
|
|
Если после элемента следует |
или
или он последний у родителя.
|
Если открывающий тег содержит один или несколько атрибутов, то тег должен указываться обязательно.
Из-за того, что многие теги можно не указывать, т.к. они подразумеваются по умолчанию, любой документ сводится к следующим частям.
Необязательная метка порядка байтов (byte order mark, BOM).
.
.
До и после доктайпа разрешается вставлять любое количество пробелов или комментариев. Таким образом, доктайп не обязательно должен располагаться в первой строке кода.
В примере 1 показан минимальный код HTML для вывода традиционного приветствия.
Пример 1. Минимальный HTML
HTML5
IE
Cr
Op
Sa
Fx
Привет, мир!
Метка порядка байтов состоит из кода символа U+FEFF в начале документа, где она используется для определения кодировки. Рекомендуется убирать этот символ, поскольку его наличие приводит к ошибкам отображения документа в некоторых браузерах. Для этого можно использовать редактор Notepad++, в меню «Кодировки» выбрать пункт «Кодировать в UTF-8 (без BOM)» (рис. 3).

Рис. 3. Выбор кодировки
Полезные ссылки
- Подробнее о метке порядка байтов
http://unicode.org/faq/utf_bom.html#bom1
- Редактор Notepad++
DOM как часть языка
В языке HTML5 впервые было введено понятие DOM (хотя он существовал и до этого, однако он не был частью языка)
, теперь HTML-документ рассматривается как набор обектов, а не тегов. Поэтому как такого синтаксиса HTML5
не существует. Однако при написании кода вы можете придерживаться правил разметки тегов
, которые были установлены в HTML 4.01 или XHTML 1.0
Синтаксис HTML 4.01
В HTML
до пятой версии, существовало несколько правил написания кода:
Свободный режим loose
, используемый в HTML 4.01
Cтрогий режим strict
, используемый в HTML 4.01
Еще был синтаксис связанный с фреймами. Фреймы в HTML5 считаются устаревшими, но многие разработчики всё равно используют их, поскольку фреймы очень удобны при разработке некоторых веб-приложений.
Синтаксис XHTML 1.0
В XHTML
, существовало два правила написания кода:
Переходный режим transitional
, используемый в XHTML 1.0
Строгий режим strict
, используемый в XHTML 1.0
Современный синтаксис HTML5
При использовании HTML5, написав в начале HTML-документа, доктайп , вы можете использовать любой из перечисленных выше синтаксисов языка (правил написания кода)
или даже совмещать HTML 4.01 и XHTML 1.0 друг с другом.
Например не обрамлять кавычками значения атрибутов атрибут=значение (свободный режим HTML 4.01 — loose)
, но в тоже время ставить слеш в одиночных тегах
(строгий режим ХHTML 1.0 — strict)
.
XHTML (strict), наиболее предпочтителен
Опытные HTML-верстальщики обычно используют при написании кода на HTML5, строгий синтаксис XHTML strict , поскольку он держит верстальщика в тонусе, не позволяет ему расслабляться и тем самым оберегает его от возможных ошибок в коде. Также использование строгого синтаксиса пригодится при изучении программирования, ибо там строгость синтаксиса, крайне важна.
Поток кодовых точек Unicode, включающий ввод в этап мнемонизации, будут первоначально виден ПАгенту как поток байтов (обычно приходящий по сети или из локальной файловой системы). Байты кодируют
реальные символы в соответствии с конкретной кодировкой символа
, которую ПА использует для декодирования байтов в символы.
Для XML-документов этот алгоритм ПАгенты должны использовать для определения кодировки символов, заданной XML-спецификацией. Этот раздел не применяется к XML-документам.
8.2.2.1 Парсинг с известной кодировкой символов
Когда HTML-парсер работает с байтовым потоком ввода, имеющим определённую известную кодировку, тогда кодировка символов – эта кодировка, а
– certain
.
8.2.2.2 Определение кодировки символов
В некоторых случаях может быть нецелесообразно однозначно определять кодировку до разбора документа. По этой причине данная спецификация предоставляет двух шаговый механизм с опционным
предварительным сканированием. В реализациях разрешается, как описано ниже, применять упрощённый алгоритм парсинга к каким бы то ни было доступным байтам до начала парсинга документа. Затем реальный
парсер стартует, с использованием предварительного кодирования, взятого из этого предварительного парсинга и других out-of-band метаданных. Если, пока документ загружается, ПА обнаруживает объявление
кодировки символов, которое конфликтует с этой информацией, тогда парсер может снова вызван для выполнения парсинга документа с реальной кодировкой.
ПАгенты должны должны использовать ниже следующий алгоритм, называемый алгоритм снифинга кодировки, для определения кодировки
символов для использования при декодировании документа в первом шаге. Этот алгоритм принимает в качестве ввода любые out-of-band метаданные, доступные ПАгенту (например,
Content-Type метаданные документа), и все доступные до сих пор байты, и возвращает кодировку символов и
, которая tentative
или certain
.
Если пользователь явно указывает ПАгенту переопределить кодировка символов документа особой кодировкой, опционно возвратить эту кодировку с
certain
Обычно ПАгенты запоминают такой запрос пользователя между сессиями и иногда применяют это также к документам в iframe ах.
ПА может больше доступных байтов ресурса либо на этом шаге, либо на более позднем шаге этого алгоритма. Например, ПА может ожидать 500ms или 1024 байт, смотря что будет первым. В целом
предварительный парсинг ресурса для определения кодировки повышает производительность, так как это уменьшает необходимость отбрасывать структуры данных, используемых при парсинге после поиска
информации кодировки.
Однако, если ПА слишком затягивает с получением данных для определения кодировки, затраты времени на ожидание могут превысить любой выигрыш от препарсинга.
Требования соответствия для декларации кодировки символов ограничивают её появление только в рамках первых 1024 байт . ПАгентам,
следовательно, рекомендуется использовать алгоритм предварительного сканирования (далее) как вызванный этими шагами на первых 1024 байтах, но не останавливаться на этом.
Для каждого ряда следующей таблицы, начиная с первого и вниз, если имеется доступных байтов больше, чем в первом столбце и первые байты файла совпадают с байтами первого столбца, тогда возвратить
кодировку из ячейки второго столбца того же ряда, с – certain
, и прервать выполнение этих шагов:
16-ричные байты
Кодировка
| FE FF
|
Big-endian UTF-16
|
| FF FE
|
Little-endian UTF-16
|
| EF BB BF
|
UTF-8
|
Этот шаг ищет Unicode Byte Order Marks (BOMs).
То, что этот шаг идёт перед следующим, соблюдающим HTTP-хедэр Content-Type , является
умышленным нарушение спецификации HTTP, что объясняется желанием быть максимально совместимым со старым содержимым.
Если транспортный слой специфицирует кодировку символов, и она поддерживается, возвратит эту кодировку с – certain
и прервать выполнение этих шагов.
UTF-8 кодирование имеет точно определяемый битовый патэрн. Документы, содержащие байты более 0x7F, совпадающие с UTF-8 патэрном, весьма вероятно, являются UTF-8, а документы с
байтовыми последовательностями, не совпадающими с ним – очень вероятно, что нет. ПАгентам, следовательно, рекомендуется искать эту общую кодировку.
Иначе – возвратить определяемую реализацией или пользователем кодировка символов по умолчанию, с – tentative
.
В управляемых окружениях или в окружениях, где кодировка документов может быть предписана (например, для ПАгенты, предназначенных конкретно для использования в новых сетях), рекомендуется
исчерпывающая кодировка UTF-8 .
В других окружениях кодировка по умолчанию обычно зависит от локали пользователя (аппроксимации языков и, таким образом, часто – кодировок страниц, которые пользователь, весьма вероятно, посещает).
Следующая таблица рекомендует умолчания на базе пользовательской локали, для совместимости со старым содержимым. Локали идентифицируются по BCP 47 тэгам языка.
Локальный язык
Рекомендуемая кодировка по умолчанию
| ar
|
Arabic
|
windows-1256
|
| ba
|
Bashkir
|
windows-1251
|
| be
|
Belarusian
|
windows-1251
|
| bg
|
Bulgarian
|
windows-1251
|
| cs
|
Czech
|
windows-1250
|
| el
|
Greek
|
ISO-8859-7
|
| et
|
Estonian
|
windows-1257
|
| fa
|
Persian
|
windows-1256
|
| he
|
Hebrew
|
windows-1255
|
| hr
|
Croatian
|
windows-1250
|
| hu
|
Hungarian
|
ISO-8859-2
|
| ja
|
Japanese
|
Shift_JIS
|
| kk
|
Kazakh
|
windows-1251
|
| ko
|
Korean
|
euc-kr
|
| ku
|
Kurdish
|
windows-1254
|
| ky
|
Kyrgyz
|
windows-1251
|
| lt
|
Lithuanian
|
windows-1257
|
| lv
|
Latvian
|
windows-1257
|
| mk
|
Macedonian
|
windows-1251
|
| pl
|
Polish
|
ISO-8859-2
|
| ru
|
Russian
|
windows-1251
|
| sah
|
Yakut
|
windows-1251
|
| sk
|
Slovak
|
windows-1250
|
| sl
|
Slovenian
|
ISO-8859-2
|
| sr
|
Serbian
|
windows-1251
|
| tg
|
Tajik
|
windows-1251
|
| th
|
Thai
|
windows-874
|
| tr
|
Turkish
|
windows-1254
|
| tt
|
Tatar
|
windows-1251
|
| uk
|
Ukrainian
|
windows-1251
|
| vi
|
Vietnamese
|
windows-1258
|
| zh-CN
|
Chinese (People"s Republic of China)
|
GB18030
|
| zh-TW
|
Chinese (Taiwan)
|
Big5
|
| Все прочие локали
|
windows-1252
|
Содержимое этой таблицы выведено из умолчаний Windows, Chrome и Firefox.
последовательность байтов, начинающуюся с байта 0x3C (ASCII Продвинуть указатель position так, чтобы он указывал на первый байт 0x3E (ASCII >), который идёт после найденного байта 0x3C.Любой другой байт
Ничего не делать с этим байтом.
Next byte
: Передвинуть position так, чтобы он указывал на следующий байт в в байтовом потоке ввода, и вернуться вверх на шаг loop
.
Поддержка кодировок на базе EBCDIC особенно не рекомендуется. Эта кодировка редко используется для публичного вэб-содержимого. Поддерживать UTF-32 также настоятельно не рекомендуется. Эта кодировка
редко используется и часто некорректно реализуется.
Данная спецификация не пытается поддерживать кодировки на базе EBCDIC и UTF-32 в своих алгоритмах; поддержка и использование этих кодировок, следовательно, может дать
непредсказуемое поведение в реализациях данной спецификации.
8.2.2.4 Определение кодировки во время парсинга
Когда парсер требует от ПА изменить кодировку, ПА должен выполнить следующие шаги. Это может произойти, если , рассмотренный выше, потерпит неудачу при поиске кодировки символов, или если он найдёт кодировку символов, которая не была фактической кодировкой файла.
8.2.2.5 Препроцессинг входного потока
Поток ввода состоит из символов, протолкнутых в него как декодированный или из различных API, которые напрямую
манипулируют потоком ввода.
Один ведущий символ U+FEFF BYTE ORDER MARK должен быть игнорирован, если они присутствуют в .
Требование вырезать символ U+FEFF BYTE ORDER MARK, независимо от того, использовался ли этот символ для определения порядка байтов, является умышленным нарушением Unicode, которое объясняется желанием повысить устойчивость ПАгентов в плане собственных транскодеров.
Любые появления любых символов из диапазонов от U+0001 до U+0008,
от U+000E до U+001F,
от U+007F
до U+009F, от U+FDD0 до U+FDEF и символов U+000B, U+FFFE, U+FFFF, U+1FFFE, U+1FFFF, U+2FFFE, U+2FFFF, U+3FFFE, U+3FFFF, U+4FFFE, U+4FFFF, U+5FFFE, U+5FFFF,
U+6FFFE, U+6FFFF, U+7FFFE, U+7FFFF, U+8FFFE, U+8FFFF, U+9FFFE, U+9FFFF, U+AFFFE, U+AFFFF, U+BFFFE, U+BFFFF, U+CFFFE, U+CFFFF, U+DFFFE, U+DFFFF, U+EFFFE, U+EFFFF, U+FFFFE, U+FFFFF, U+10FFFE и U+10FFFF
являются . Все они – управляющие символы или перманентно неопределённые/undefined Unicode-символы(несимволы/noncharacters).
Символы "CR" (U+000D) и "LF" (U+000A) рассматриваются особо. Все символы CR должны быть конвертированы в символы LF, а любые символы LF, которые идут после символа CR,
должны игнорироваться. Таким образом, новые строки/newlines в HTML DOM представлены символами LF и никогда – символами CR во вводе к этапу .
Следующий символ ввода это первый символ в , который ещё не использован/consumed или явно
игнорируется требованиями этого раздела. Начально
это первый символ в потоке ввода. Текущий символ
ввода это последний символ, который был
.
Точка вставки/точка вставки это позиция (непосредственно перед символом или непосредственно перед концом потока ввода), где содержимое, вставленное с использованием
document.write() , реально вставляется. Точка вставки является относительной к позиции символа сразу
после неё, это не абсолютное смещение в потоке ввода. Начально точка вставки не определена/undefined.
Символ "EOF" в последующих таблицах это концептуальный символ, представляющий конец . Если парсер это
парсер, созданный скриптом , тогда конец достигается, когда используется
явный символ "EOF"
(вставленный методом document.close()). Иначе символ "EOF" – это не реальный символ в
потоке, а обозначение отсутствия любых последующих символов.
Обработка символов U+0000 NULL варьируется в зависимости от того, где символы находятся. В целом они игнорируются, кроме случаев, когда это может реально подставить по удар.
Такая обработка, по необходимости, распространяется на стадии мнемонизации и построения дерева.
| |